[KT Cloud TechUp] 크롤링 실습 (feat. 정규표현식)
October 16, 2025
1. IP 주소 확인 사이트에서 현재 컴퓨터의 공인 IP 주소 자동으로 추출하기
from selenium import webdriver
url = 'https://ipipip.kr'
driver = webdriver.Chrome()
driver.get(url)
html_code = driver.page_source
driver.quit()
웹사이트 접속 및 HTML 소스 가져오기: ipipip.kr 사이트에 접속한 뒤 전체 HTML 소스코드를 html_code 변수에 저장하고 브라우저를 종료함
html_code_line_list = html_code.split('\n')
for html_code_line in html_code_line_list:
if html_code_line.find("data-clipboard-text") >= 0:
print(html_code_line)
cut_line = html_code_line
break
HTML을 줄 단위로 분할한 뒤 data-clipboard-text 속성이 포함된 줄을 찾음. 이 속성에 IP 주소가 저장되어 있음
clipboard_len = len("data-clipboard-text")
cut_line = cut_line[cut_line.find("data-clipboard-text")+clipboard_len+2:]
cut_line2 = cut_line[:cut_line.find("\"")]
print(cut_line2)
input()
문자열 파싱 과정
예를 들어 HTML 라인이 와 같다고 하면 clipboard_len = 18, +clipboard_len+2 = 20 (따옴표와 등호 건너뛰기), cut_line = “192.168.1.100” class=”Btn”>복사</button>, cut_line_2 = “192.168.1.100”
2. 1번 실습에서 정규표현식 사용해서 파싱하기
from selenium import webdriver
import re
# re > regular expression / 정규표현식
url = 'https://ipipip.kr'
driver = webdriver.Chrome()
driver.get(url)
html_code = driver.page_source
regex_pattern = re.compile("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}")
m = regex_pattern.search(html_code)
print(m.group())
driver.quit()
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}에서 \d{1,3}은 숫자 3개, .은 점 문자 (escape 필요) => 총 4개의 숫자 그룹이 점을 연결된 패턴을 추출함
3. 2번 실습에서 정규표현식 개선
from selenium import webdriver
import re
url = 'https://ipipip.kr'
driver = webdriver.Chrome()
driver.get(url)
html_code = driver.page_source
regex_pattern = re.compile("(?:(?:25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)\.){3}(?:25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)")
m = regex_pattern.search(html_code)
print(m.group())
driver.quit()
2번 코드에서는 단순히 숫자 1-3자리만 체크해 잘못된 IP도 허용되는 문제가 있었다.
| regex_pattern = re.compile(“(?:(?:25[0-5] | 2[0-4]\d | 1\d\d | [1-9]?\d).){3}(?:25[0-5] | 2[0-4]\d | 1\d\d | [1-9]?\d)”) |
25[0-5] -> 250 ~ 255 2[0-4]\d -> 200 ~ 249 1\d\d -> 100 ~ 199 [1-9]?\d -> 0 ~ 99 (?:…): 비캡처 그룹 (그룹화는 하지만 결과를 저장하지 않음) {3}: 앞의 패턴을 3번 반복 (첫 3개 옥텟) 마지막 옥텟은 별도로 한번 더 검사함 (.때문에)
4. 이메일 주소 검증/추출 정규표현식
import re
#re.compile(r'''([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+(\.[a-zA-Z]{2,4}){1,2})''')
regex_pattern = re.compile(r'''(
[a-zA-Z0-9._%+-]+ # ID
@
[a-zA-Z0-9.-]+ # domain name / naver daum
(\.[a-zA-Z]{2,4}){1,2} # dot-something / .com .net .co.kr
)''', re.VERBOSE)
test1 = "asdfsdc3535@naver.com"
output = regex_pattern.search(test1).group()
print(output)
re.VERBOSE가 하는 일: 정규표현식 안의 공백 무시, 줄바꿈 허용, 주석 사용 가능
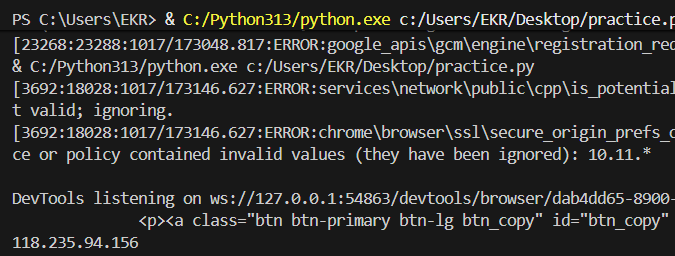
5. 웹 프록시 목록 사이트에서 HTTPS URL들을 정규표현식으로 추출
import re
from selenium import webdriver
url = 'https://www.free-webproxy-list.kr/'
driver = webdriver.Chrome()
driver.get(url)
html_code = driver.page_source
무료 웹 프록시 목록 사이트에 접속해 전체 html 소스를 획득
regex_pattern = re.compile('https\:\/\/([a-z-0-9]+\.){0,}[a-z-0-9]+')
output = regex_pattern.finditer(html_code)
for domain in output:
print(domain)
https가 아니거나, 대문자거나, 2단계 도메인 문제가 있는 링크들을 걸러 준다.
6. 네이버 블로그 검색 자동화 프로그램 골격
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
url = 'https://www.naver.com'
keyword = "보안 회사"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element(By.CLASS_NAME, "search_input").send_keys(f"{keyword}\n")
time.sleep(3) # 3초 정도 대기
네이버 메인 페이지 접속 -> 검색창에 “보안 회사” 입력 후 엔터, 3초 대기 (검색 결과 로딩)
# 첫 번째 방법: click event를 주고 블로그 탭을 들어가는법
# driver.find_element(By.LINK_TEXT, "블로그").click()
# 두 번째 방법:
driver.get(f"https://search.naver.com/search.naver?ssc=tab.blog.all&sm=tab_jum&query={keyword}")
input()
블로그 탭 이동 후 사용자가 엔터 누를 때까지 대기
 아무리봐도 자동으로 움직이는 크롬 참 신기하다.
아무리봐도 자동으로 움직이는 크롬 참 신기하다.
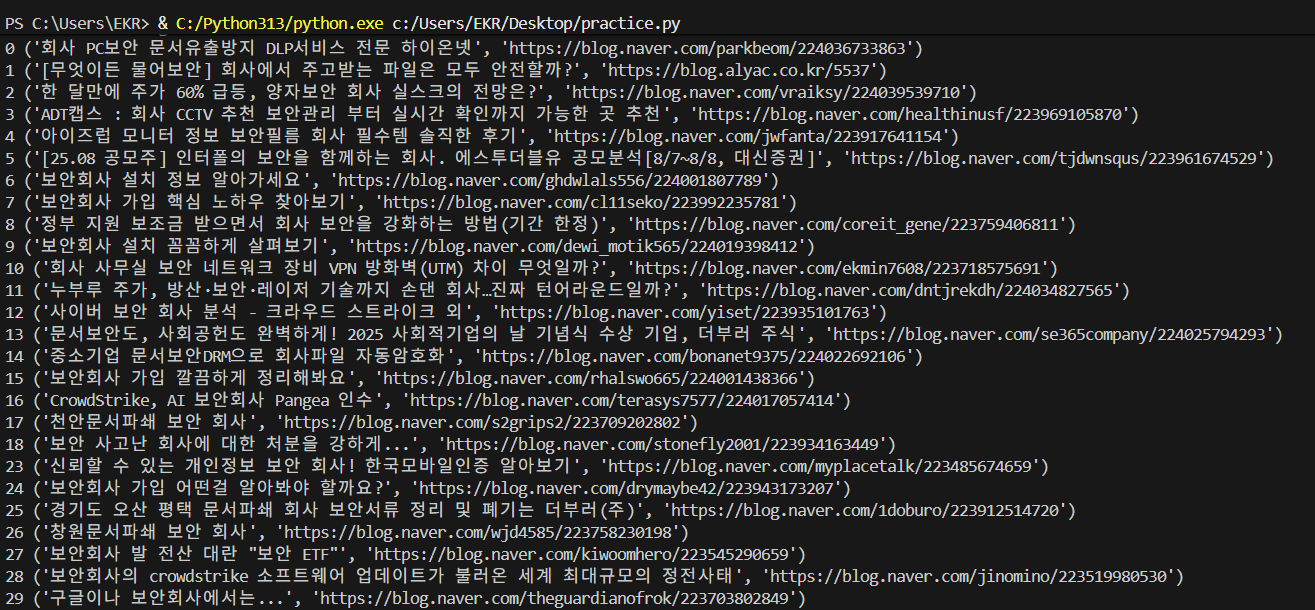
7. 네이버 블로그 검색 자동화 프로그램 완성
import re
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
import time
url = 'https://www.naver.com'
keyword = "보안 회사"
driver = webdriver.Chrome()
driver.get(url)
driver.find_element(By.CLASS_NAME, "search_input").send_keys(f"{keyword}\n")
time.sleep(3) # 3초 정도 대기
driver.get(f"https://search.naver.com/search.naver?ssc=tab.blog.all&sm=tab_jum&query={keyword}")
# 1. PAGE DOWN (키)
for i in range(1, 10):
driver.find_element(By.TAG_NAME, "body").send_keys(Keys.PAGE_DOWN)
time.sleep(0.5)
blog_elements = driver.find_elements(By.CLASS_NAME, "Pcw4FFPrGxhURyUmBGxh")
for blog_i, blog_element in enumerate(blog_elements):
blog_title = blog_element.text
blog_url = blog_element.get_attribute('href')
row_tuple = (blog_title, blog_url)
print(blog_i, row_tuple)
input()
위와 같이 동작하지만 스크롤해서 더 많은 결과를 로드하고, 블로그 요소들을 수집한 뒤 제목과 URL을 추출하여 출력한다.