[KT Cloud TechUp] exploit-db 크롤링하기
October 20, 2025
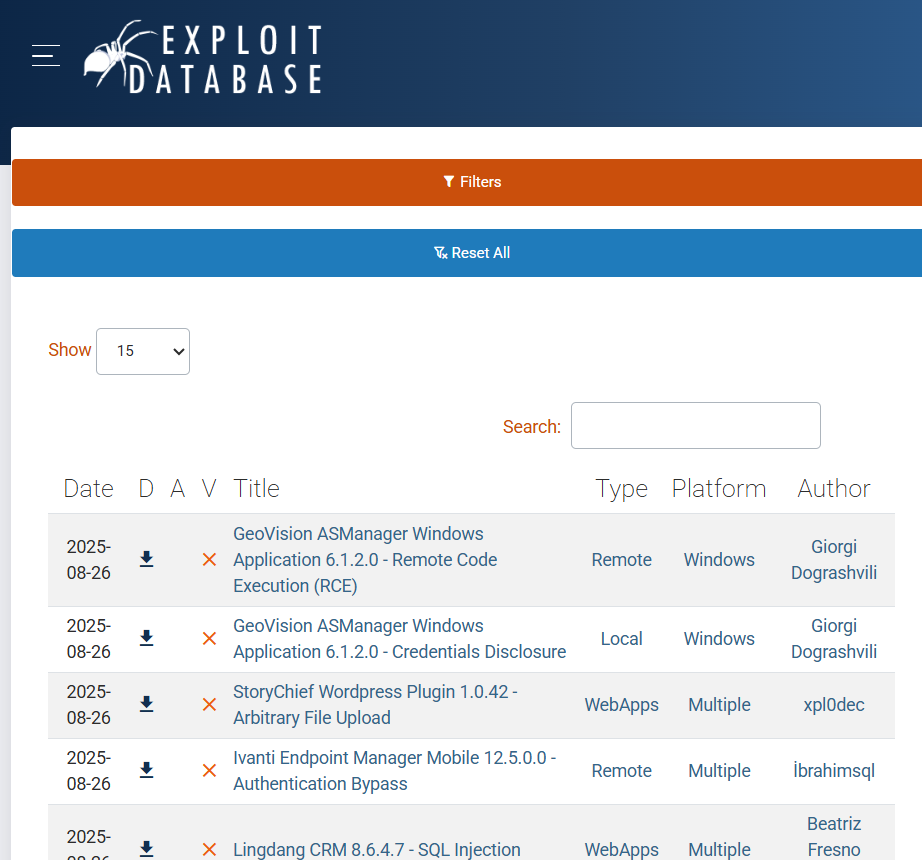 https://www.exploit-db.com/ 이 사이트의 취약점 제목들을 크롤링해 csv 형태로 저장하는 것이 과제였다.
https://www.exploit-db.com/ 이 사이트의 취약점 제목들을 크롤링해 csv 형태로 저장하는 것이 과제였다.
제목 크롤링
1단계
아침 9시라 아무 생각 없이 request로 HTML 받아와서 파싱하는 방법으로 크롤링 하다가 결과가 계속 0개가 나와서 뭐지… 하고 ai한테 물어봤더니 selenium 쓰라고 말해줘서 아차 했다.
import requests
from bs4 import BeautifulSoup
import csv
def crawl_exploit_db():
url = "https://www.exploit-db.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# exploit 링크들 찾기
exploit_links = soup.find_all('a', href=lambda x: x and '/exploits/' in x)
vulnerabilities = []
for link in exploit_links:
title = link.text.strip()
if title and len(title) > 10:
vulnerabilities.append([title])
# CSV 저장
with open('exploits.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Title'])
writer.writerows(vulnerabilities)
crawl_exploit_db()
2단계 - Selenium 도입
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def crawl_with_selenium():
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.exploit-db.com/")
time.sleep(5)
# exploit 링크 찾기
links = driver.find_elements(By.CSS_SELECTOR, 'a[href*="/exploits/"]')
for link in links:
title = link.text.strip()
if title:
print(f"발견: {title}")
driver.quit()
결과: 1개만 수집됨 문제: 대부분의 링크에서 .text가 비어있음. 첫 번째 항목만 텍스트가 로드됨
3단계 - HTML 구조 분석
개발자 도구에서 HTML 구조를 확인해 보니
<tr role="row" class="even">
<td>2025-08-26</td>
<td>...</td>
<td>...</td>
<td>...</td>
<td>
<a href="/exploits/52424">GeoVision ASManager Windows Application 6.1.2.0 - Remote Code Execution (RCE)</a>
</td>
<td>...</td>
<td>...</td>
<td>...</td>
</tr>
이런 식으로 되어 있었다. 즉 5번째 컬럼에 제목이 들어가 있는 것을 확인할 수 있음.
# 5번째 컬럼 타겟팅
title_elements = driver.find_elements(By.CSS_SELECTOR, "tbody tr td:nth-child(5) a")
for element in title_elements:
title = element.text.strip()
if title and len(title) > 10:
print(f"발견: {title}")
코드를 이렇게 바꿔서 실행했지만 여전히 1개만 수집되었다…
4단계 - 디버깅 지옥
상세 디버깅을 해 보니
for i, element in enumerate(elements, 1):
text = element.text.strip()
href = element.get_attribute('href')
innerHTML = element.get_attribute('innerHTML')
print(f"{i}. text: '{text}'")
print(f" href: {href}")
print(f" HTML: {innerHTML}")
HTML에는 제목이 있는데 .text로는 빈 문자열이 나온다. 이는 Lazy Loading 때문인 것을 알 수 있었다.
5단계 - BeautifulSoup + Selenium
Selenium으로 페이지를 로드하고, BeautifulSoup으로 HTML 소스를 파싱해보았다.
from selenium import webdriver
from bs4 import BeautifulSoup
def crawl_final():
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.exploit-db.com/")
time.sleep(10)
# 핵심: 페이지 소스를 BeautifulSoup으로 파싱
soup = BeautifulSoup(driver.page_source, 'html.parser')
vulnerabilities = []
exploit_links = soup.find_all('a', href=lambda x: x and '/exploits/' in x)
for link in exploit_links:
title = link.get_text(strip=True)
if title and len(title) > 10:
vulnerabilities.append([title])
driver.quit()
return vulnerabilities
결과: 분명 웹사이트에는 취약점이 15개씩 나왔는데 10개만 찾음. 이유: 페이지 로딩이 완전히 되지 않았거나, 다른 날짜의 데이터도 포함되어 있거나, 더 긴 대기 시간이 필요했기 때문이라고 생각해 로딩 시간을 늘리고, 다른 날짜의 데이터도 포함되도록 했다.
최종 코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import csv
import time
def crawl_exploit_db_complete():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
try:
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.exploit-db.com/")
print("페이지 로딩 중...")
time.sleep(15) # 충분한 대기 시간
# 테이블 로딩 완료 확인
for i in range(10):
try:
info_element = driver.find_element(By.CSS_SELECTOR, ".dataTables_info")
if "Showing" in info_element.text:
print(f"테이블 로딩 완료: {info_element.text}")
break
except:
pass
time.sleep(2)
time.sleep(5)
# BeautifulSoup으로 파싱 (핵심!)
soup = BeautifulSoup(driver.page_source, 'html.parser')
vulnerabilities = []
exploit_links = soup.find_all('a', href=lambda x: x and '/exploits/' in x)
for link in exploit_links:
title = link.get_text(strip=True)
if title and len(title) > 15: # 의미있는 제목만
if [title] not in vulnerabilities:
vulnerabilities.append([title])
print(f"{len(vulnerabilities)}. {title}")
if len(vulnerabilities) >= 15:
break
# CSV 저장
with open('exploit_db_vulnerabilities.csv', mode='w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Vulnerability Title'])
writer.writerows(vulnerabilities)
print(f"\n총 {len(vulnerabilities)}개의 취약점이 저장되었습니다!")
except Exception as e:
print(f"오류: {e}")
finally:
driver.quit()
if __name__ == "__main__":
crawl_exploit_db_complete()
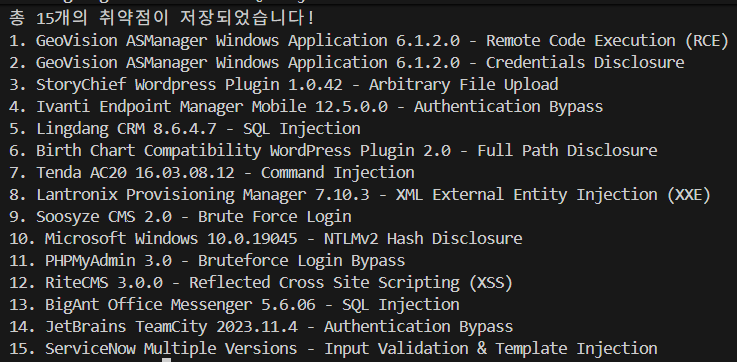 굿!
굿!
다운로드 링크 크롤링
제목과 다운로드 링크 모두 exploit id를 사용한다는 점을 발견했다. 예를 들면 제목 링크도 /exploits/52424, 다운로드 링크도 /download/52424로 되어 있다.
# 이전 버전 - 제목만
exploit_links = soup.find_all('a', href=lambda x: x and '/exploits/' in x)
for link in exploit_links:
title = link.get_text(strip=True)
if title and len(title) > 15:
vulnerabilities.append([title]) # 1개 컬럼
기존에 이렇게 되어 있던 코드에
# 업그레이드 - 다운로드 링크도 함께
download_links = soup.find_all('a', href=lambda x: x and '/download/' in x)
title_links = soup.find_all('a', href=lambda x: x and '/exploits/' in x)
print(f"다운로드 링크 {len(download_links)}개 발견")
print(f"제목 링크 {len(title_links)}개 발견")
다운로드 링크 수집을 추가했다.
# 핵심 아이디어: ID로 매칭
download_dict = {}
for link in download_links:
href = link.get('href')
exploit_id = href.split('/')[-1] # "52424" 추출
download_dict[exploit_id] = f"https://www.exploit-db.com{href}"
# 제목과 다운로드 링크 매칭
for link in title_links:
title = link.get_text(strip=True)
href = link.get('href')
if title and len(title) > 15:
exploit_id = href.split('/')[-1] # "52424" 추출
download_url = download_dict.get(exploit_id, "")
if download_url:
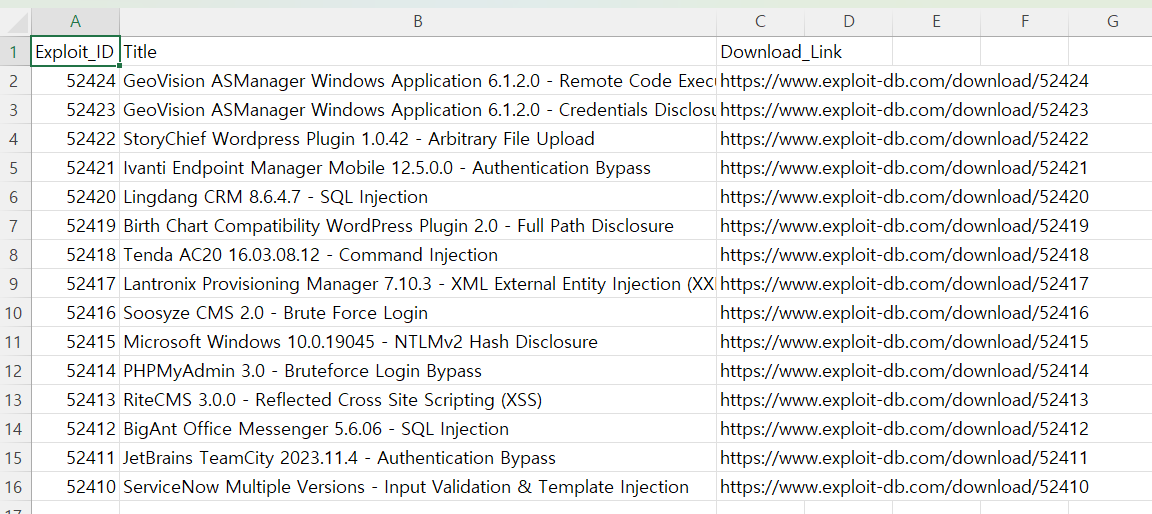
vulnerabilities.append([exploit_id, title, download_url]) # 3개 컬럼
id를 이용해 제목과 다운로드 링크를 매치해서 최종적으로는 아래와 같은 코드가 나왔다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import csv
import time
def crawl_exploit_db_with_downloads():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
try:
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.exploit-db.com/")
print("페이지 로딩 중...")
time.sleep(15)
# 테이블 로딩 완료 대기
for i in range(10):
try:
info_element = driver.find_element(By.CSS_SELECTOR, ".dataTables_info")
if "Showing" in info_element.text:
print(f"테이블 로딩 완료: {info_element.text}")
break
except:
pass
time.sleep(2)
time.sleep(5)
# BeautifulSoup으로 파싱
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 1. 다운로드 링크 수집
download_links = soup.find_all('a', href=lambda x: x and '/download/' in x)
print(f"다운로드 링크 {len(download_links)}개 발견")
# 2. 제목 링크 수집
title_links = soup.find_all('a', href=lambda x: x and '/exploits/' in x)
print(f"제목 링크 {len(title_links)}개 발견")
# 3. ID 기반 다운로드 딕셔너리 생성
download_dict = {}
for link in download_links:
href = link.get('href')
exploit_id = href.split('/')[-1]
download_dict[exploit_id] = f"https://www.exploit-db.com{href}"
# 4. 제목과 다운로드 링크 매칭
vulnerabilities = []
for link in title_links:
title = link.get_text(strip=True)
href = link.get('href')
if title and len(title) > 15:
exploit_id = href.split('/')[-1]
download_url = download_dict.get(exploit_id, "")
if download_url:
vulnerabilities.append([exploit_id, title, download_url])
print(f"{len(vulnerabilities)}. ID: {exploit_id}")
print(f" 제목: {title[:50]}...")
print(f" 다운로드: {download_url}")
print("-" * 50)
# 5. CSV 저장 (3개 컬럼)
csv_path = "exploit_db_with_downloads.csv"
with open(csv_path, mode='w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Exploit_ID', 'Title', 'Download_Link'])
writer.writerows(vulnerabilities)
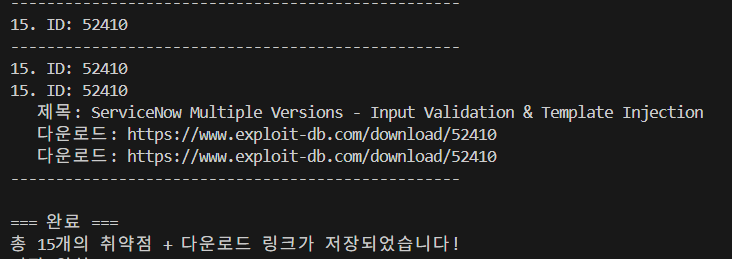
print(f"\n=== 완료 ===")
print(f"총 {len(vulnerabilities)}개의 취약점 + 다운로드 링크가 저장되었습니다!")
print(f"저장 위치: {csv_path}")
return vulnerabilities
except Exception as e:
print(f"오류: {e}")
finally:
try:
driver.quit()
except:
pass
if __name__ == "__main__":
results = crawl_exploit_db_with_downloads()
CVE 번호까지 크롤링하기
각 취약점마다 https://www.exploit-db.com/exploits/52424와 같이 /{id}로 들어가서 CVE 번호까지 크롤링하도록 기능 추가
def get_cve_from_exploit_page(driver, exploit_url, exploit_id):
try:
print(f"CVE 정보 수집 중: {exploit_url}")
driver.get(exploit_url)
time.sleep(5)
soup = BeautifulSoup(driver.page_source, 'html.parser')
#방법 1: code 태그에서 검색
code_elements = soup.find_all('code', class_='language-txt')
for code in code_elements:
text = code.get_text()
cve_match = re.search(r'CVE-\d{4}-\d{4,7}', text)
if cve_match:
print(f"발견된 CVE: {cve_match.group()}")
return cve_match.group()
#방법 2: pre 태그에서 검색
pre_elements = soup.find_all('pre')
for pre in pre_elements:
text = pre.get_text()
cve_match = re.search(r'CVE-\d{4}-\d{4,7}', text)
if cve_match:
print(f"발견된 CVE: {cve_match.group()}")
return cve_match.group()
#방법 3: 전체 페이지에서 cve 패턴 탐색
page_text = soup.get_text()
cve_matches = re.findall(r'CVE-\d{4}-\d{4,7}', page_text)
if cve_matches:
unique_cves = list(set(cve_matches))
print(f"발견된 CVE: {unique_cves}")
return unique_cves[0]
print(f"CVE 정보 없음")
return "N/A"
except Exception as e:
print(f"CVE 정보 수집 오류: {e}")
return "ERROR"
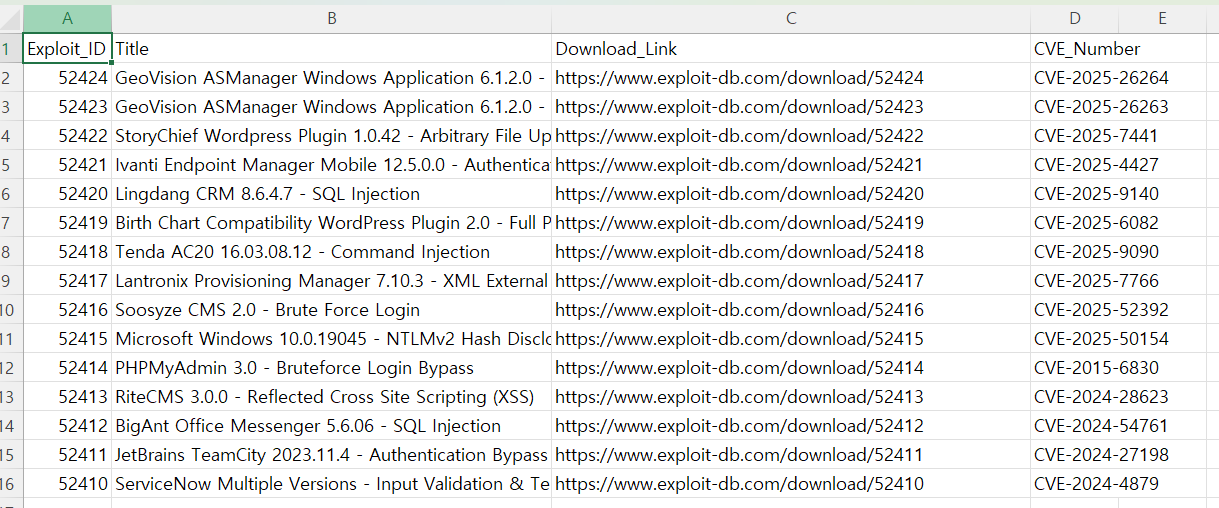 굿뜨!
굿뜨!