[2SeC] Terraform? OpenSearch? + 파이프라인 구조
December 04, 2025
Terraform
- IaC 도구로, 코드를 사용해 인프라를 정의하고 프로비저닝할 수 있게 한다.
1. 주요 개념
- Provider: Terraform이 클라우드(AWS, Azure 등) 또는 서비스 API와 통신하기 위해 사용하는 플러그인. 예를 들어 AWS 리소스를 만들려면 aws Provider를 설정해야 함.
- Resource: 실제로 생성할 인프라 지원 (예: aws_instance, aws_vpc, opensearch_domain 등)
- State: Terraform이 관리하는 실제 인프라의 최신 상태를 기록하는 파일 (기본적으로 terraform.tfstate)
- Remote State: 협업과 안정적인 관리를 위해 S3와 같은 외부 스토리지에 상태 파일을 저장하는 방식(Backend 설정)을 사용함. Terraform이 인프라를 생성/변경할 때 이 상태 파일을 참조하여 현재 코드와 실제 인프라의 차이점 파악함.
- Module: 공통으로 사용하거나 재사용할 인프라 코드를 한 곳에 모아서 정의한 단위. 코드를 간결하게 유지하고 표준화하는데 유용함.
- HCL (HashiCorp Configuration Language): Terraform 구성을 작성하는 선언적 언어
2. 핵심 명령어
Terraform의 작업 흐름은 일반적으로 init -> plan -> apply 순서이다.
(1) terraform init: 작업 디렉토리 초기화 - 필요한 Provider를 다운로드하고 Backend 설정 준비 (2) terraform plan: 실행 계획 확인 - 작성한 코드와 현재 State를 비교하여 어떤 변경 사항이 생길지 미리 예측 결과를 보여줌. 실제 리소스 변경은 일어나지 않음. (3) terraform apply: 인프라 적용 - Plan에서 생성된 실행 계획에 따라 실제 인프라를 생성/변경함 (4) terraform destroy: 인프라 삭제 - Terraform이 관리하는 모든 리소스를 삭제함 (5) terraform validate: 문법 검사 - 구성 파일의 구문이 유효한지 검사.
OpenSearch
1. 주요 개념
- Cluster: OpenSearch 인스턴스들의 집합
-
Node: 클러스터 내에서 검색, 인덱싱, 데이터 저장을 담당하는 서버
- Master Node: 클러스터 관리(노드 추가/제거, 인덱스 생성/삭제 등) 담당
- Data Node: 실제 데이터를 저장하고 검색 및 집계 요청을 처리함
- Index: 관계형 데이터베이스의 테이블과 유사하게, 관련된 문서들을 모아둔 논리적인 컨테이너. 데이터를 쿼리하는 기본 단위.
- Document: 인덱스에 저장되는 기본 데이터 단위로 JSON 형식으로 저장됨
-
Shard: 인덱스를 수평 분할한 단위
- Primary Shard: 문서가 저장되는 원본 샤드
- Replica Shard: 프라이머리 샤드의 복제본으로, 검색 처리량을 늘리고 장애 발생 시 데이터 손실을 방지함
- OpenSearch Dashboards: OpenSearch에 저장된 데이터를 시각화하고 탐색할 수 있는 웹 인터페이스 (Kibana)
2. 검색 및 분석 기능
- 풀 텍스트 검색
- 역 인덱스: 검색 성능을 높이기 위해 문서에 포함된 모든 단어를 인덱싱하는 구조
- 집계 (Aggregation): 데이터에서 통계 및 메트릭을 계산하는 기능
- 벡터 검색 (Vector Search/KNN): 데이터를 벡터로 변환해 의미론적 유사성을 기반으로 검색하는 기능 (RAG에 사용됨)
3. 데이터 관리 및 운영
- ISM (Index State Management): 인덱스의 수명 주기(Hot/Warm/Cold 스토리지로 이동, 삭제 등)를 자동으로 관리하는 기능
- Hot/UltraWarm/Cold Storage: 데이터 액세스 빈도에 따라 노드 유형을 분리하여 비용 효율성을 높임. (자주 사용 - Hot, 가끔 사용 - UltraWarm)
- 보안: OpenSearch는 기본적으로 인증, 권한 관리, 전송 계층 보안 (TLS) 등을 위한 강력한 보안 플러그인을 제공함.
Terraform을 활용한 인프라 구축 단계별 정리
우리 팀의 인프라 구성도
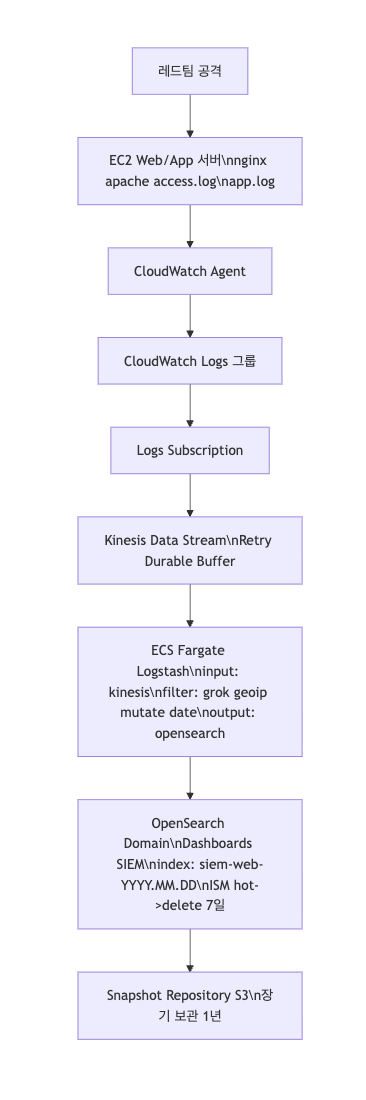
1. 네트워크 및 기반 환경 구축 (VPC)
- 네트워크 (VPC, Subnet) 생성
- 보안그룹 생성: 방화벽 역할
- EC2 생성: Public/Private Subnet 및 보안 그룹 연결
2. 로그 수집 및 전송 파이프라인 구축
- Kinesis Stream 생성: 데이터의 버퍼링 및 내구성을 담당하는 핵심 스트림
- 권한 설정(IAM): CloudWatch Logs가 Kinesis Stream에 데이터를 넣을 수 있도록, 그리고 ECS Fargate가 Kinesis에서 데이터를 읽을 수 있도록 권한 정의
- CloudWatch Logs: EC2에서 CloudWatch Agent를 통해 로그가 수집되는 저장소
- Logs Subscription: CloudWatch Logs 그룹과 Kinesis Data Stream을 연결하는 역할
3. 로그 처리 및 변환
Kinesis에서 로그를 읽어와 구조화하고(grok), 위치 정보(geoip)를 추가하는 등의 가공 작업을 수행하고 OpenSearch로 전송
- Logstash 환경 (ECS Cluster): 컨테이너(Logstash)가 실행될 환경
- Logstash 정의 (ECS Task Definition): Logstash 컨테이너 이미지, CPU/메모리, 환경 변수, Kinesis에서 읽고 OpenSearch에 쓰는 권한 가진 IAM 역할 필요
- Logstash 실행 (ECS Service): 정의된 Logstash TAsk를 Fargate 환경에서 실행하고 관리. Logstash의 Input/Filter/Output 설정은 보통 컨테이너 이미지에 포함하거나 Task Definition을 통해 전달
4. 검색 엔진 및 장기 보관
- OpenSearch Domain(OpenSearch Service): 검색 엔진 클러스터 자체. VPC, Subnet, 보안 그룹 설정 및 노드 유형(Hot/Ultra Warm/Cold)를 정의
- OpenSearch Index(OpenSearch API): 인덱스 템플릿 등을 정의할 수 있음. OpenSearch 도메인이 준비되면 Logstash가 자동으로 인덱스를 생성하도록 구성할 수도 있음
- 인덱스 관리: ISM 정의
- 스냅샷 S3: 장기 보관 위한 백업 저장소
- 스냅샷 정책 (OpenSearch API): OpenSearch가 S3 버킷에 스냅샷 저장할 수 있도록 권한 부여 + 정책 설정
파이프라인 구조
EC2 Logs
→ CloudWatch Agent
→ CloudWatch Logs
→ Subscription Filter
→ Kinesis
→ Logstash(Fargate)
→ OpenSearch
→ Dashboards
→ S3 Snapshot
이렇게 파이프라인을 구성했다.
-
CloudWatch
- AWS 자원들의 로그와 메트릭을 수집/보관하는 모니터링 서비스
- ClodWatch Logs: EC2에서 나오는 애플리케이션 로그, 시스템 로그를 로그 스트림 형태로 저장해 줌.
- 얘를 만들어둬야 뒤에서 Subscription Filter로 다른 서비스(kinesis, lambda 등)으로 흘려보낼 수 있음
-
Kinesis (Amazon Kinesis Data Streams)
- 대량의 로그/이벤트 데이터를 스트리밍 방식으로 수집/전달하는 서비스
- ClodWatch에 들어온 로그를 실시간 스트림 형태로 Kinesis로 흘려보내는 단계
- 위에서 ClodWatch가 로그를 올려두면 아래에서 Logstash가 로그를 읽어감
-
Logstash (Fargate 위에서 도는 컨테이너)
- Logstash 자체는 오픈소스 로그 수집/가공 도구의 일부임.
- 여러 소스에서 로그를 받아서 필터로 가공을 하고 원하는 저장소로 내보내주는 파이프라인 도구
- Logstash는 실행 파일이라 어디서든 돌릴 수 있는데, Fargate를 쓰면 EC2 직접 관리 안 해도 되고, 스케일 조정이 편하고, 컨테이너 이미지 버전만 관리하면 돼서 인프라 부담이 적음.
- Kinesis에서 로그를 읽고 -> 로그 포맷을 파싱해서 필드를 쪼개고 -> OpenSearch가 인덱싱하기 좋게 JSON 문서 형태로 정리해서 OpenSearch로 전송함
-
OpenSearch
- ElasticSearch에서 파생된 분산 검색/분석 엔진
- 로그/이벤트 데이터 인덱싱, 필터/쿼리 검색, aggregation(통계/차트/관계 분석), 시각화
- Logstash가 보내준 정리된 로그를 인덱스에 저장하고 보안 분석/오류 분석/트래픽 패턴 분석 등에 사용함
- 위에 Dashboard를 붙여서 시각화/대시보드/탐색 쿼리를 할 수 있게 해줌